Apprentissage
Un modèle neuronal logique qui se contente de mettre en jeu des fonctions d'activation ou d'inhibition reste limité aux options logiques de base : et, ou, vrai, faux. Le ou inclusif pose déjà problème à ce stade. Selon la conception connexionniste des neurones artificiels, deux questions se posent : d'une part, quel est le meilleur modèle de connexion des neurones entre eux et, d'autre part, comment ajuster la pondération des signaux d'entrée à chaque connexion neuronale de manière à ce qu'une machine puisse apprendre, c'est-à-dire ajuster les poids accordés aux signaux et trouver les « bons chemins » dans le réseau neuronal.
Sur la première question, c'est vers les neurosciences qu'on va se tourner, et plus particulièrement vers les travaux de Donald Hebb en 1949. D. Hebb a découvert que le poids synaptique (la « valeur » du signal) est renforcé lorsque deux neurones sont activés simultanément. On appelle cela l'apprentissage associatif : une association est faite (et mémorisée) par répétition de stimuli qui renforcent les liens neuronaux. En termes mathématiques, le modèle de D. Hebb revient à dire que si un neurone \(Na\) est relié à un neurone \(Nb\), en vertu de sa sortie \(Sa\), alors le poids synaptique \(Wab\) est calculé comme la somme de l'état de \(Wab\) à l'instant \(t\) ajouté au produit de \(Sa\) et \(Sb\) lui-même multiplié par un facteur de poids \(\eta\) compris entre \(0\) et \(1\).
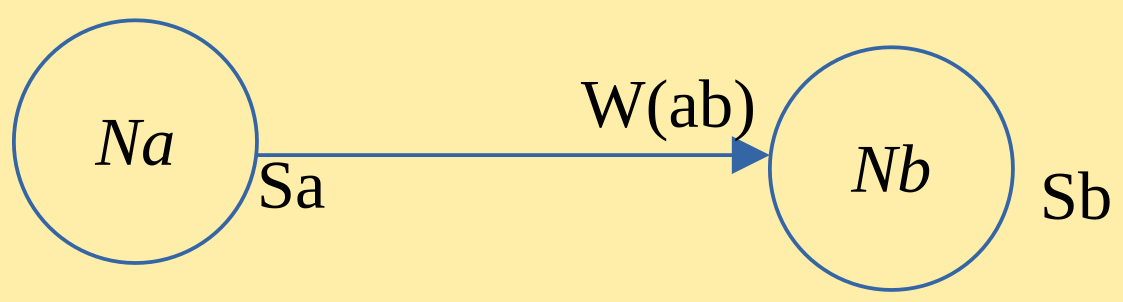
Soit :
\(Wab(t+1)=Wab(t)+\eta \times Sa \times Sb\)
avec \(0 < \eta \leq 1\).
Pour répondre à la seconde question, il fallait essayer un modèle concret. En 1957, Frank Rosenblatt invente le Mark-I Perceptron, une machine électronique capable de reconnaître des formes simples. À la règle de Hebb, qui promet déjà une forme d'apprentissage, il ajoute une autre variable : le résultat attendu (une fonction seuil qui conditionne la connexion). Le Perceptron est conçu pour reconnaître des lettres de l'alphabet à l'aide de capteurs photo-électriques. Imaginons des couches de neurones dont chaque neurone est connecté à ceux de la couche suivante. Il s'agit d'ajuster les résultats jusqu'à ce que les coefficients synaptiques permettent de reconnaître les formes avec un taux de succès de 100 %… ou approchant. Cela revient à renforcer ou diminuer les poids synaptiques en fonction de l'erreur constatée.
Suivant ce même principe, les fonctions d'apprentissage des modèles d'IA procèdent par itération de manière à appliquer des algorithmes (comme la méthode de descente de gradient, la régression, la fonction de perte...) afin de déterminer les rapports entre les poids et les erreurs. L'apprentissage consiste à faire traiter par le réseau neuronal un grand nombre de données d'entrée, à comparer les résultats obtenus avec les résultats attendus, à ajuster les poids, et à recommencer ce processus encore et encore.
Ce principe est évidemment simplifié. Aujourd'hui, les grands modèles de langage (LLM) multiplient les « paramètres », jusqu'à les dénombrer en milliards. Cette multiplication du nombre de poids synaptiques et d'ajustements est rendue possible grâce aux avancées techniques (au prix de l’utilisation d'une grande quantité d'énergie) et aux bonnes recettes mathématiques disponibles.